



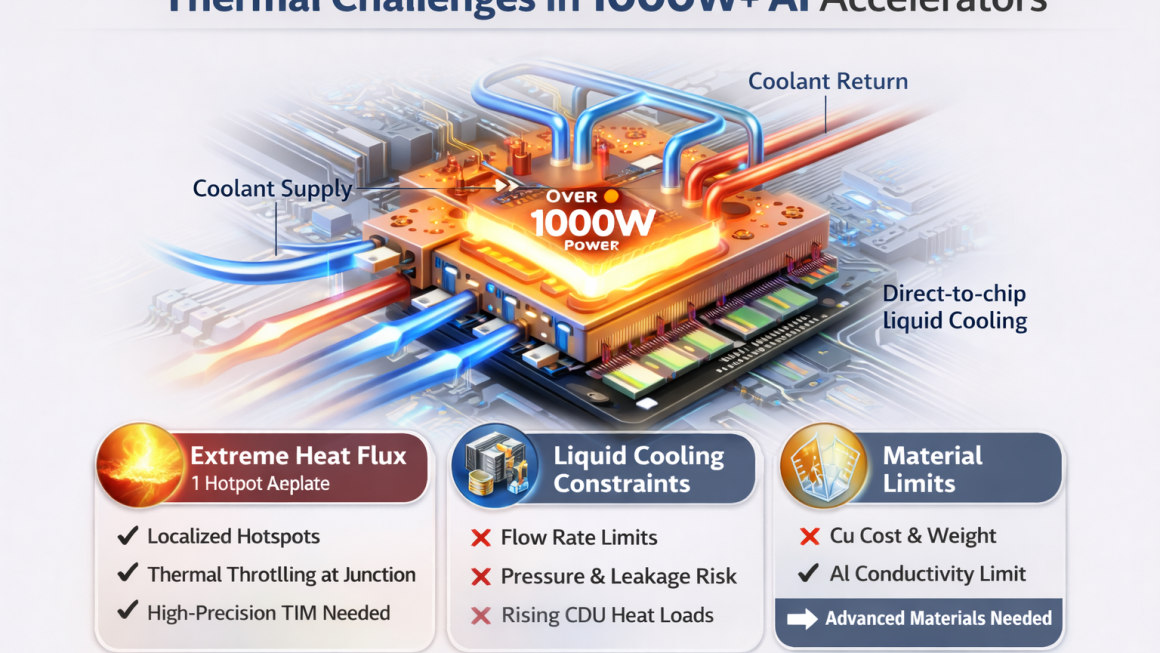
Entering the 1000W Era
AI infrastructure is rapidly moving beyond traditional power limits. With next-generation GPUs and AI accelerators approaching or exceeding 1000W per chip, thermal management is no longer an optimization problem—it is a fundamental system constraint.
At this level, conventional cooling approaches begin to fail, and even standard liquid cooling designs face new physical and engineering limits.
1. Extreme Heat Flux at the Chip Level
The biggest challenge is not total power—but heat density.
- Power: 800W → 1200W
- Die size does not scale proportionally
- Result: Localized heat flux skyrockets
This leads to:
- Hotspots forming within microseconds
- Uneven temperature distribution across the die
- Increased risk of thermal throttling
👉 Even small interface inefficiencies (TIM, flatness, pressure) can result in significant performance loss.
2. Limits of Conventional Liquid Cooling
Direct-to-chip liquid cooling is already widely adopted—but at 1000W+, new bottlenecks appear:
Key constraints:
- Coolant flow rate limits (pump power vs efficiency)
- Pressure drop across microchannels
- Flow distribution imbalance in multi-chip systems
Problem:
Increasing flow is not always viable—it increases:
- Energy consumption
- System complexity
- Risk of leakage and failure
3. Thermal Interface Bottlenecks
Between the chip and cold plate lies the thermal interface layer (TIM)—often the weakest link.
Challenges include:
- High thermal resistance at ultra-high heat flux
- Pump-out and degradation over time
- Surface flatness and mounting pressure sensitivity
At 1000W+, TIM performance directly determines:
- Junction temperature (Tj)
- Long-term reliability
- System stability
4. Material Limitations in Cold Plates
Traditional materials are reaching their limits:
Copper:
- Excellent conductivity
- But heavy and expensive
- Scaling challenges in large systems
Aluminum:
- Lightweight and scalable
- But lower conductivity → requires design optimization
Emerging solutions:
- Hybrid structures (Cu + Al)
- Graphene-enhanced coatings
- Advanced surface engineering for improved heat transfer
👉 Material choice is no longer standalone—it must be co-designed with flow and structure.
5. System-Level Heat Rejection Challenges
Even if chip-level cooling works, the heat must still be removed from the system.
At rack level:
- 100kW+ heat loads are becoming common
- CDU (Coolant Distribution Unit) capacity becomes critical
- Facility water temperature constraints limit efficiency
At data center level:
- Cooling infrastructure must evolve (liquid loops, dry coolers, immersion systems)
- Energy efficiency (PUE) becomes harder to maintain
6. Reliability and Risk at High Power Density
Higher power → higher risk:
- Thermal cycling stress on materials
- Increased probability of leakage in liquid systems
- Component aging accelerated by temperature gradients
Downtime cost in AI clusters is extremely high, making reliability as important as performance.
7. The Path Forward: Integrated Thermal Design
Solving 1000W+ challenges requires a holistic approach:
Key directions:
- Co-design of:
- Chip
- Packaging
- Thermal interface
- Cold plate
- Advanced materials:
- High-performance TIMs
- Coatings (graphene, nano-structured surfaces)
- Smarter flow design:
- Microchannel optimization
- Parallel cooling architectures
The transition to 1000W+ AI accelerators marks a turning point.
Thermal management is no longer a supporting function—it is a core enabler of AI performance and scalability.
Companies that can integrate:
- Materials
- Thermal engineering
- System design
will define the next generation of AI infrastructure.