



Performance Is Not Enough
As AI infrastructure scales, achieving high performance is only the first step. The real challenge lies in maintaining and scaling systems over time.
👉 This is where serviceability and modular design become critical.
In modern AI environments:
- Systems run 24/7 under heavy load
- Downtime is extremely costly
- Hardware evolves rapidly
A well-designed system must not only perform—but also be easy to service, upgrade, and scale.
1. What Is Serviceability in AI Systems?
Serviceability refers to how easily a system can be:
- Maintained
- Repaired
- Upgraded
- Diagnosed
Key aspects:
- Accessibility of components
- Speed of replacement
- Safety during maintenance
- Minimal disruption to operations
👉 Poor serviceability leads to longer downtime and higher operational costs.
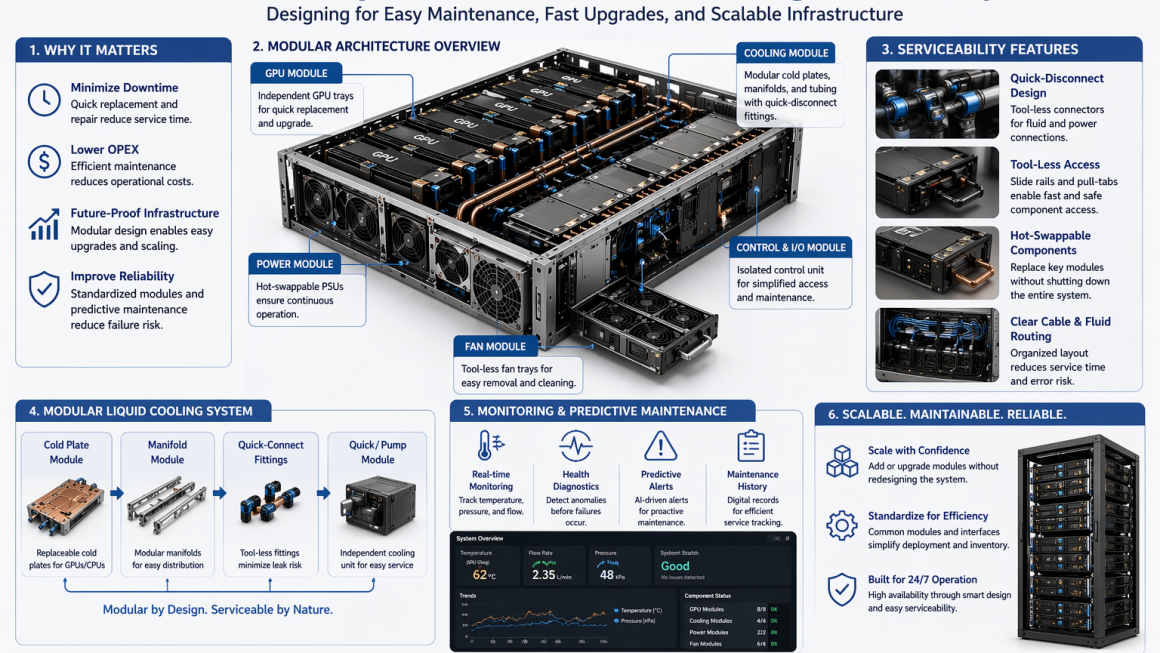
2. The Role of Modular Design
Modular design breaks a system into independent, replaceable units.
Examples in AI infrastructure:
- GPU modules
- Liquid cooling modules (cold plates, manifolds)
- Power supply units (PSUs)
- Rack-level cooling distribution systems
Benefits:
- Faster maintenance
- Simplified upgrades
- Improved scalability
- Reduced system complexity during servicing
👉 Modular systems are easier to deploy, expand, and maintain at scale.
3. Challenges in High-Density AI Systems
Limited Physical Access
- Dense GPU configurations restrict access
- Liquid cooling adds tubing and connections
Complex Interconnections
- Power, data, and fluid systems are tightly integrated
- Maintenance requires coordination across multiple systems
Risk During Servicing
- Potential for coolant leaks
- Risk of damaging sensitive components
👉 Without modularity, maintenance becomes time-consuming and risky.
4. Design Principles for Serviceable AI Systems
Front and Rear Accessibility
- Key components should be reachable without full system disassembly
Tool-Less or Minimal-Tool Design
- Quick-release mechanisms
- Simplified connectors
Standardized Interfaces
- Uniform connectors for:
- Power
- Cooling
- Data
Clear Component Separation
- Logical grouping of modules
- Reduced interference between systems
5. Modular Design in Liquid Cooling Systems
Liquid cooling introduces unique serviceability challenges—but also opportunities.
Modular approaches include:
- Quick-disconnect fittings for fluid lines
- Replaceable cold plate assemblies
- Modular manifolds for rack-level distribution
- Pre-assembled cooling loops
Benefits:
- Faster maintenance without draining the entire system
- Reduced risk of leakage during servicing
- Easier system upgrades
6. Material and Structural Considerations
Material selection impacts serviceability:
Lightweight Materials (e.g., Aluminum)
- Easier handling during installation and replacement
- Reduced physical strain and risk
Durable Materials
- Withstand repeated assembly/disassembly cycles
- Maintain sealing integrity over time
Surface Treatments
- Corrosion resistance
- Improved durability in liquid environments
👉 Good material choices reduce both maintenance effort and long-term failure risk.
7. Monitoring and Predictive Maintenance
Modern AI systems integrate intelligent monitoring:
- Temperature sensors
- Flow and pressure monitoring
- Leak detection systems
- Performance analytics
These enable:
- Early fault detection
- Predictive maintenance
- Reduced unexpected downtime
👉 Serviceability is no longer reactive—it is becoming proactive and data-driven.
8. Scalability Through Modularity
AI infrastructure must scale rapidly.
Modular design enables:
- Adding new GPU nodes without redesigning the system
- Expanding cooling capacity incrementally
- Standardizing deployment across multiple sites
👉 This is critical for hyperscale and enterprise AI deployments.
Designing for the Full Lifecycle
Serviceability and modular design are essential for:
- Reducing downtime
- Lowering operational costs
- Enabling rapid scaling
- Improving system reliability
The most effective AI systems are those designed not just for performance at launch, but for ease of operation over years of continuous use.
👉 In next-generation AI infrastructure, success depends on how well systems can be maintained, upgraded, and scaled—not just how fast they compute.